Scraping Websites for Data with Nokogiri
This is one of the first tools that I’ve learned to use and instantly felt how powerful it is. Nokogiri is a web scraping tool used to parse and search HTML, XML and other documents. It’s simple to use and actually kinda fun. For my first project with it, I built a web scraper that grabs the information for the top books of every century from Goodreads.
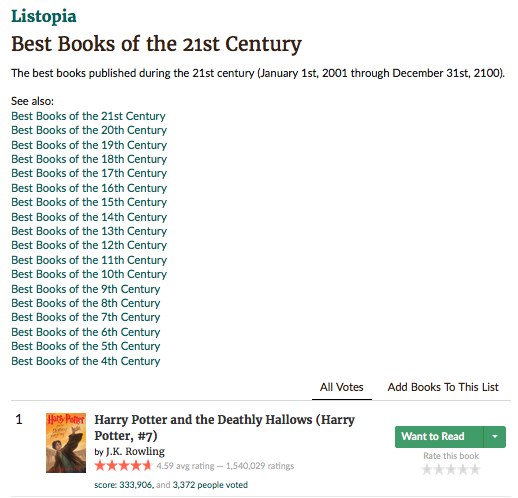
An Outline of this Project
In planning out this project, I envisioned three stages of interaction.
- The user chooses the decade for which they want to see the top books.
- The program returns a list of the top books for that specific decade.
- The user then can get more information about a specific book, like descriptions and ratings.
This means building a few methods, one that scrapes information on the decades, one that gathers information on each book and a CLI (Command Line Interface) to interact with these data. (Yes, the word data is plural).
Scraping the Decade Information from Goodreads
We can open, read and parse HTML Pages by requiring both Nokogiri and Open-URI at the top of our document. Then I set the opened Nokogiri document equal to a variable called decades. All of this is contained within the Decade class and a class method called scraper. So Decade.scraper does exactly what it sounds: scrapes information on the decades.
require 'nokogiri'
require 'open-uri'
Class Decade
@@all = []
def self.scraper
decades = Nokogiri::HTML(open("https://www.goodreads.com/list/show/7")) #The page of each decade
decades.css("div.mediumText a").each do |scrape| #Each link is iterated over
if scrape.text.include?("Century") #if that link includes the text "centuries", continue
decade = self.new #make a new decade object
decade.name = scrape.text.strip.gsub("Best Books of the ", "")
#sets the name equal to the link text, but changes it with gsub
decade.url = scrape.attr("href")
#saves the link to that decade, which we'll need in a moment.
decade
@@all << decade #saves this decade object into the @@all global variable.
end
end
end
endYou’ll notice the decades.css line above. .CSS is a nokogiri method that allows us to narrow in on any part of the HTML document based on CSS classes and IDs. Here, the links for each decade are listed, so I iterate through each one.
This gives us some nice and tidy data:
[#<BestBooks::Decade:0x007fb2d521f978 @name="21st Century", @url="https://www.goodreads.com/list/show/7", @top10=nil>,
#<BestBooks::Decade:0x007fb2d521f3b0 @name="20th Century", @url="https://www.goodreads.com/list/show/6", @top10=nil>
#etcGathering Book Information for each Decade
So each decade has a top ten books. As the data get scraped above, it doesn’t include the information on the top ten books of that decade: @Top10 = nil. I need to write code that opens each URL for the decade, pulls the data for each book and returns an array of those books, stored in the @Top10 attribute of the decade.
To do this, I built a Book class which has a scrape class method. The code below is commented to explain it’s purpose. Basically, the information for each book is stored in a table row, so for each table row, I grab the needed information.
Class Book
attr_accessor :ranking, :title, :link, :author, :rating, :description, :decade
def self.scrape(link) #the link argument is where I can pass the URL of each decade
books = Nokogiri::HTML(open(link)) #Nokogiri will open up that URL here
@top10books = [] #This is where we'll store the data on the books
books.search("tr").each do |this| #iterate through each table row
if this.css("td.number").text.to_i <= 10
#this pulls only the first 10. Some decades have 100 books, which we don't want
libro = BestBooks::Book.new
#a new instance of the Book class, set to the variable libro
#setting all the information by scanning the CSS
libro.ranking = this.css("td.number").text
libro.title = this.css("a.bookTitle span").text
libro.link = this.css("a.bookTitle").attr("href").value
libro.author = this.css(".authorName span").text
libro.rating = this.css(".minirating").text.strip
#I'm proud of figuring this one out. Finder here is equal to a second Nokogiri link
#which opens the link of the book itself to scrape the text of the description,
#which is then set as the description attribute.
finder = Nokogiri::HTML(open("https://www.goodreads.com" + libro.link))
libro.description = finder.css("#description span").text
libro
@top10books.push(libro) #pushes all the book information into an array.
else
this
end
end
return @top10books #after iterating through the top10 books, returns the completed array.
end
endNow, to integrate this data with my Decade objects, I created the Decade.books class method.
def self.books
@@all.each do |geturl|
bookscraper = BestBooks::Book.scrape(geturl.url) #passing the URL to the Book.scrape method mentioned above
top10 = []
top10 = bookscraper
geturl.top10 = top10
end
@@all
endThis method iterates through @@all the decades, grabs the URL of that decade and passes it to the Book.scrape method. When the book scraper returns the array of the top ten books, it sets that array equal to the @Top10 attribute of the Decade object.
So the data for each decade now look like this:
[#<BestBooks::Decade:0x007fdba3335d20 @name="21st Century", @url="https://www.goodreads.com/list/show/7",
@top10=[#<BestBooks::Book:0x007fdba424b850
@ranking="1",
@title="Harry Potter and the Deathly Hallows (Harry Potter, #7)",
@link="/book/show/136251.Harry_Potter_and_the_Deathly_Hallows",
@author="J.K. Rowling",
@rating="4.59 avg rating — 1,542,081 ratings",
@description="Harry is waiting in Privet Drive... etc">,
#<BestBooks::Book:0x007fdba33e70c0
@ranking="2",
@title="The Hunger Games (The Hunger Games, #1)",
@link="/book/show/2767052-the-hunger-games",
@author="Suzanne Collins",
@rating="4.37 avg rating — 4,050,120 ratings",
@description="Winning will make you famous. Losing means certain death... etc">
#etc, for all 10 books, for each decade. It's a lot of data. Building a Command Line Interface
To be able to interact with this information, I’ve built a command line interface. The code is available on my github and this video below shows a walkthrough of the program.
Time to Refactor
So this works to achieve a function, but can do so much more elegantly. I plan on refactoring to:
- Work more quickly by storing the information instead of scraping it each time.
- To be more graceful in it’s construction.
Stay tuned for the refactored update and the publication of the final gem.